

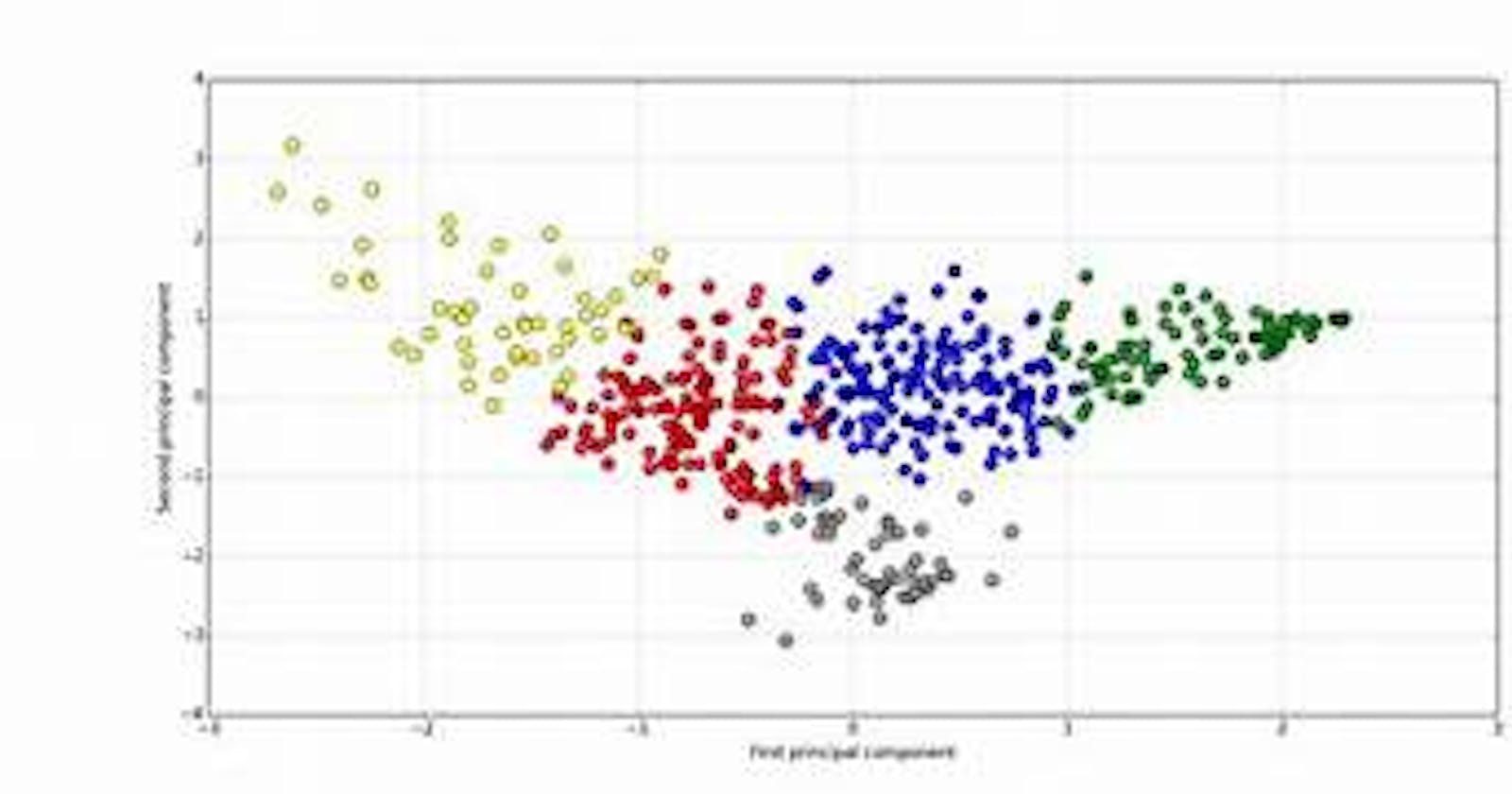


Basically, cluster analysis is the distribution of data points into various clusters. The criteria of distributing them into various clusters is such that there must be similarity between datapoints in same cluster and difference in data points between different clusters.
The more the similarity between data points between same cluster and the more difference in betweeen data points of different clusters, the more distinct is the clustering.
Clustering: Identifying objects of similar types
Types of clustering:
Partitional Clustering: Dataset is divided into clusters, i.e., set of groups, separate k value can be taken for centroid based method. We need to pre-specify the no. of clusters.
Hierarchial Clustering: Set of nested clustering, organized by representation of a tree. Usually visualized by a dendrogram.
Exclusive Clustering: Assigning each object to a single group, i.e, non-overlapping clustering.
Non-exclusive Clustering: Objects in one group can also be present in other groups, i.e, objects can simultaneously belong to one or more than one group.
It is overlapping clustering.
Fuzzy Clustering: Based on membership weight concept.
Every object should have a minimum weight between 0 and 1.
Clusters are treated as fuzzy sets.
Complete Clustering: Assign every object to a cluster, no object should be left.
Every object is desired.
Partial Clustering: Some objects does not have groups or are not clustered properly. It does not have desired object.
Well-separated Clustering: Threshold used to specify that all the objects in a cluster must be sufficiently close (or similar) to one another.
The distance between any two points in different groups is larger than the distance between any two points within a group.
Prototype based Clustering: For data with continuous attributes, the prototype of a cluster is often a centroid, i.e., the average (mean) of all the points in the cluster.
Prototype is a medoid (the most representative point of a cluster) for categorical attributes.
For many types of data, the prototype is the most central point, and commonly referred as center-based clusters. Such clusters are globular.
Graph Based Clustering: If the data is represented as a graph, where the nodes are objects and the links represent connections among objects then a cluster can be defined as a connected component; i.e., a group of objects that are connected to one another, but that have no connection to objects outside the group.
Density based: A cluster is a dense region of objects that is surrounded by a region of low density. A density-based definition of a cluster employed when the clusters are irregular or intertwined, and when noise and outliers are present. E.g., DBSCAN Algorithm